Architecting a Modern Data Pipeline: AWS, Snowflake, dbt & the Medallion Architecture
Introduction
Scalable data pipelines are not built by chance. They are intentionally designed around strong architectural principles: separation of concerns, metadata-driven transformations, reproducibility, observability, and governance.
Lately, I have been exploring an end-to-end data architecture built with AWS, Snowflake, and dbt, structured around the medallion architecture. The goal is to move data from raw ingestion to trusted, business-ready outputs in a way that is secure, maintainable, and ready to scale.
Rather than treating the pipeline as a simple extract-load-transform flow, this architecture treats each stage as a distinct engineering layer with a specific purpose. That clarity makes the system easier to evolve, test, and govern over time.
Bronze Layer: AWS S3 and Snowflake as the Ingestion Foundation
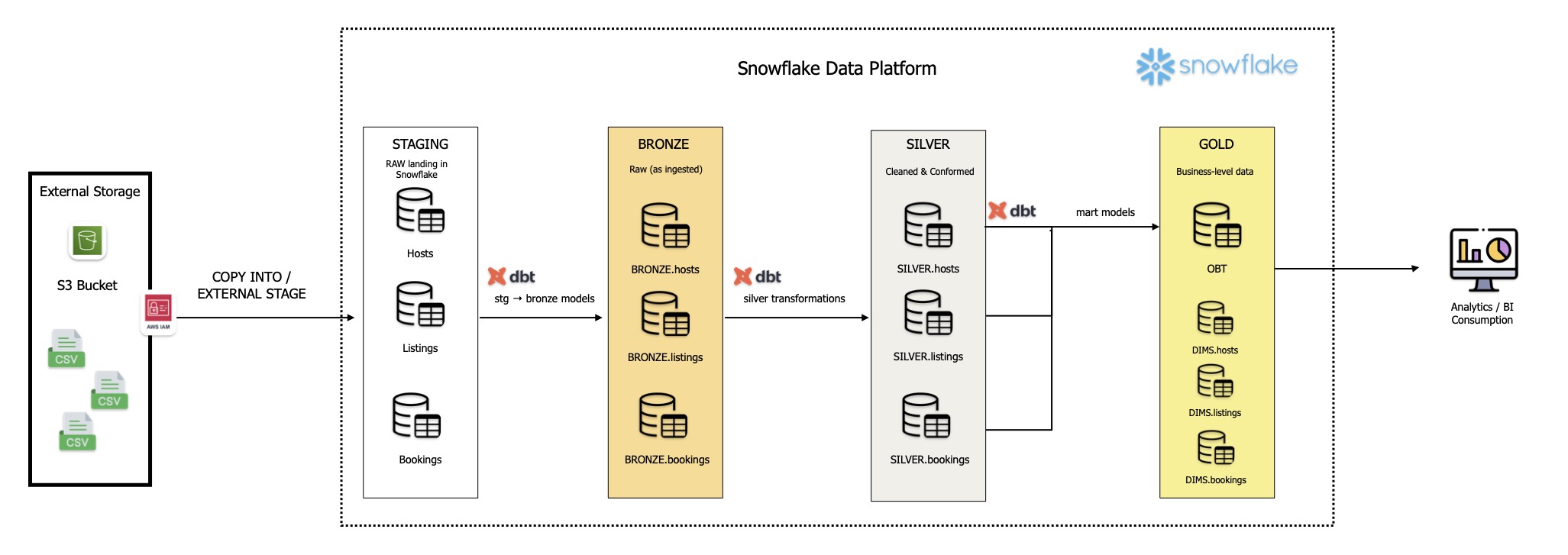
The pipeline begins with external CSV files being landed into an AWS S3 bucket, which acts as the raw landing zone and durable object storage layer. S3 is well suited for this role because it provides scalable, cost-effective storage for source data before any transformation occurs.
Security is built into the ingestion process from the start. AWS IAM is used to establish controlled access between Snowflake and the S3 bucket, following least-privilege principles. This ensures that Snowflake can read only the required objects, without exposing broader access than necessary.
Inside Snowflake, external stages are configured to reference the S3 location, and custom external file formats are defined to standardise how incoming files are parsed. This is an important detail because raw source files are rarely perfectly consistent. Defining file formats explicitly helps manage delimiters, header rows, null handling, encoding, and other load-time assumptions in a controlled way.
This first layer forms the Bronze layer of the medallion architecture: raw, minimally processed data preserved as close as possible to its original state. That matters because the Bronze layer provides lineage, traceability, and the ability to reprocess source data if business rules or downstream logic change. Snowflake sits at the centre of this layer as the warehouse and governance engine, providing secure storage and scalable compute for the rest of the pipeline.
Silver Layer: dbt as the Transformation Engine
Once raw data is ingested, the next challenge is not simply storing it, but shaping it into a clean and consistent analytical foundation. That is where the Silver layer comes in, and where dbt becomes the core transformation framework.
dbt enables an ELT pattern, where raw data is loaded first and transformed inside the warehouse afterwards. This is a powerful design choice because it allows Snowflake to handle the heavy lifting of transformation while dbt provides the orchestration, modularity, and structure around those transformations.
From an engineering perspective, dbt replaces large monolithic SQL scripts with modular models that are easy to understand, version-control, and test. Each model has a clear purpose and can depend on upstream models through dbt's built-in lineage framework. That means transformation logic is not just documented in theory — it is encoded directly into the project structure.
Jinja templating and macros further improve maintainability by reducing repetition and standardising repeated SQL patterns. Instead of copying and pasting similar logic across multiple models, reusable macros make transformations more composable and consistent. Combined with Git and GitHub, this creates a development workflow that is much closer to software engineering best practice than traditional ad hoc SQL development.
The result is a Silver layer built from cleaned, conformed, and reusable intermediate datasets. This layer is where source data begins to become trustworthy analytical data.
Historical Tracking with SCD Type 2
A mature analytics platform does not only care about the latest state of a record. It also needs to understand how that record changed over time.
To support this, dbt snapshots can be used to implement Slowly Changing Dimension Type 2 behaviour. This is especially useful when attributes evolve over time, such as a customer changing their profile, a host updating property details, or a product record being revised.
Instead of overwriting historical values, SCD Type 2 preserves prior versions of the record with effective dates and versioning metadata. This allows downstream consumers to answer questions like: what did the data look like at the time? What changed between two reporting periods? Which records were active during a specific window?
That historical context is essential for accurate reporting, auditability, and point-in-time analysis. It is one of the clearest signs of a warehouse that has moved beyond basic ingestion and into genuinely mature modelling.
Gold Layer: Dimensional Models and One Big Table Outputs
The Gold layer is where the data becomes consumption-ready for analytics, dashboards, and business reporting. At this point, the data has been cleaned, conformed, and historically managed, so the modelling approach can focus on usability and performance.
One strategy is the traditional star schema. Here, fact and dimension tables are designed to support flexible analytical querying. This pattern works particularly well for BI environments because it keeps business measures in fact tables and descriptive context in dimension tables, enabling drill-down analysis and consistent metric definition.
Alongside that, a One Big Table can also be produced for use cases where simplicity and query performance matter more than normalised modelling. By joining conformed datasets into a single denormalised structure, the OBT reduces query complexity for BI tools and makes it easier for consumers to access data without needing to understand warehouse joins or relational design.
This dual approach is practical because not every consumer needs the same modelling pattern. Some teams need the rigour of a star schema, while others benefit from the speed and simplicity of a flattened analytical table.
Why This Architecture is Effective
What makes this architecture strong is not just the individual tools, but how they work together.
AWS S3 provides scalable raw storage. Snowflake provides secure, elastic warehousing and governance. dbt provides modular, metadata-driven transformations and modelling discipline. GitHub introduces version control and collaboration. And the medallion architecture gives the system a clear progression from raw data to trusted outputs.
Together, they create a pipeline that is secure, observable, maintainable, and built for scale. It is not just about moving data from one place to another. It is about designing an engineering system that can absorb change, preserve history, and deliver reliable data products for the business.
That is what modern data architecture should look like: structured, transparent, and built with intent.